8.3. Reading CSV files#
To ensure great compatibility between Kinetics Toolkit and other frameworks, TimeSeries can be converted from and to Pandas DataFrame using the ktk.TimeSeries.from_dataframe and ktk.TimeSeries.to_dataframe methods. Therefore, as long as a data file can be opened in Pandas, it can then be converted to a TimeSeries, as shown in Fig. 8.1.
Comma Separated Values (CSV) files are ubiquitous in research. They are text files where values are separated usually by commas, but sometimes by other delimiters such as ; or tabs. The first line often contains labels to indicate the nature of each column. Here is the content of a typical CSV file:
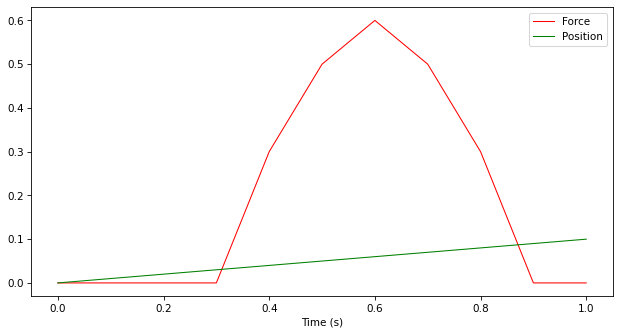
Time,Force,Position
0,0,0
0.1,0,0.01
0.2,0,0.02
0.3,0,0.03
0.4,0.3,0.04
0.5,0.5,0.05
0.6,0.6,0.06
0.7,0.5,0.07
0.8,0.3,0.08
0.9,0,0.09
1,0,0.1
First, we will read it as a DataFrame using pd.read_csv:
import kineticstoolkit.lab as ktk
import pandas as pd
df = pd.read_csv(
ktk.doc.download("timeseries_dataframe_example1.csv"),
index_col="Time",
)
df
| Force | Position | |
|---|---|---|
| Time | ||
| 0.0 | 0.0 | 0.00 |
| 0.1 | 0.0 | 0.01 |
| 0.2 | 0.0 | 0.02 |
| 0.3 | 0.0 | 0.03 |
| 0.4 | 0.3 | 0.04 |
| 0.5 | 0.5 | 0.05 |
| 0.6 | 0.6 | 0.06 |
| 0.7 | 0.5 | 0.07 |
| 0.8 | 0.3 | 0.08 |
| 0.9 | 0.0 | 0.09 |
| 1.0 | 0.0 | 0.10 |
Important
Note the use of the index_col parameter. This is the name of the column that corresponds to time. It is always required to correctly convert the DataFrame to a TimeSeries.
We now convert the DataFrame to a TimeSeries:
ts = ktk.TimeSeries.from_dataframe(df)
ts.plot()
8.3.1. Importing multidimensional data#
In the first example, the force sensor was unidimensional; however, for a tridimensional force sensor, we would expect three signals (x, y, z). In this new example, we will import the following CSV file:
Time,Fx,Fy,Fz,Position
0,0,-9.81,0,0
0.1,0,-9.81,0,0.01
0.2,0,-9.81,0,0.02
0.3,0,-9.81,0,0.03
0.4,0.3,-9.81,1.5,0.04
0.5,0.5,-9.81,2.5,0.05
0.6,0.6,-9.81,3,0.06
0.7,0.5,-9.81,2.5,0.07
0.8,0.3,-9.81,1.5,0.08
0.9,0,-9.81,0,0.09
1,0,-9.81,0,0.1
We first read the CSV file as a DataFrame:
df = pd.read_csv(
ktk.doc.download("timeseries_dataframe_example2.csv"),
index_col="Time",
)
df
| Fx | Fy | Fz | Position | |
|---|---|---|---|---|
| Time | ||||
| 0.0 | 0.0 | -9.81 | 0.0 | 0.00 |
| 0.1 | 0.0 | -9.81 | 0.0 | 0.01 |
| 0.2 | 0.0 | -9.81 | 0.0 | 0.02 |
| 0.3 | 0.0 | -9.81 | 0.0 | 0.03 |
| 0.4 | 0.3 | -9.81 | 1.5 | 0.04 |
| 0.5 | 0.5 | -9.81 | 2.5 | 0.05 |
| 0.6 | 0.6 | -9.81 | 3.0 | 0.06 |
| 0.7 | 0.5 | -9.81 | 2.5 | 0.07 |
| 0.8 | 0.3 | -9.81 | 1.5 | 0.08 |
| 0.9 | 0.0 | -9.81 | 0.0 | 0.09 |
| 1.0 | 0.0 | -9.81 | 0.0 | 0.10 |
Then we import this DataFrame as a TimeSeries:
ts = ktk.TimeSeries.from_dataframe(df)
ts.data
{
'Fx': array([0. , 0. , 0. , 0. , 0.3, 0.5, 0.6, 0.5, 0.3, 0. , 0. ])
'Fy': <array of shape (11,)>
'Fz': array([0. , 0. , 0. , 0. , 1.5, 2.5, 3. , 2.5, 1.5, 0. , 0. ])
'Position': <array of shape (11,)>
}
The CSV file was correctly read as a TimeSeries. However, force components are scattered into three separate arrays. Would it be possible to read it as one Nx3 array instead?
To this effect, simply rename the columns of the DataFrame, either in the original CSV file or after reading it, using index brackets as it would be accessed in the resulting array:
df.columns = ["Forces[:,0]", "Forces[:,1]", "Forces[:,2]", "Position"]
df
| Forces[:,0] | Forces[:,1] | Forces[:,2] | Position | |
|---|---|---|---|---|
| Time | ||||
| 0.0 | 0.0 | -9.81 | 0.0 | 0.00 |
| 0.1 | 0.0 | -9.81 | 0.0 | 0.01 |
| 0.2 | 0.0 | -9.81 | 0.0 | 0.02 |
| 0.3 | 0.0 | -9.81 | 0.0 | 0.03 |
| 0.4 | 0.3 | -9.81 | 1.5 | 0.04 |
| 0.5 | 0.5 | -9.81 | 2.5 | 0.05 |
| 0.6 | 0.6 | -9.81 | 3.0 | 0.06 |
| 0.7 | 0.5 | -9.81 | 2.5 | 0.07 |
| 0.8 | 0.3 | -9.81 | 1.5 | 0.08 |
| 0.9 | 0.0 | -9.81 | 0.0 | 0.09 |
| 1.0 | 0.0 | -9.81 | 0.0 | 0.10 |
We can now import this new DataFrame as a TimeSeries, with the three force signals combined in one Nx3 array:
ts = ktk.TimeSeries.from_dataframe(df)
ts.data
{
'Forces': <array of shape (11, 3)>
'Position': <array of shape (11,)>
}
ts.data["Forces"]
array([[ 0. , -9.81, 0. ],
[ 0. , -9.81, 0. ],
[ 0. , -9.81, 0. ],
[ 0. , -9.81, 0. ],
[ 0.3 , -9.81, 1.5 ],
[ 0.5 , -9.81, 2.5 ],
[ 0.6 , -9.81, 3. ],
[ 0.5 , -9.81, 2.5 ],
[ 0.3 , -9.81, 1.5 ],
[ 0. , -9.81, 0. ],
[ 0. , -9.81, 0. ]])
For series of arrays with more than one dimension, the brackets would have multiple indexes. For example, a series of Nx4x4 homogeneous matrices would require 16 columns and the indexes would go from [0,0] to [3,3].